Excel易用宝教程:Excel提取唯一值
Excel提取唯一值算是比较常见的,如果需要处理的数据区域是一列,那么可以通过高级筛选或者Excel自带的删除重复值功能给予快速解决,但当数据源区域是一行甚至多行多列的二维区域,那么Excel没有对应的工具进行快速处理呢?试试Excel易用宝吧。
Excel易用宝的“提取唯一值”功能,无论数据源区域是一列,还是一行,抑或是多行多列的二维区域都能快速处理。
-

Excel易用宝 v1.1.0 官方安装版
授权:免费版软件大小:7.38MB语言:简体中文
Excel易用宝是一款由Excel Home开发团队打造的拥有极致效率,多版兼容,持久动力等特色的Excel工具箱,据说是目前最实用的Excel工具箱哦。
操作方法:
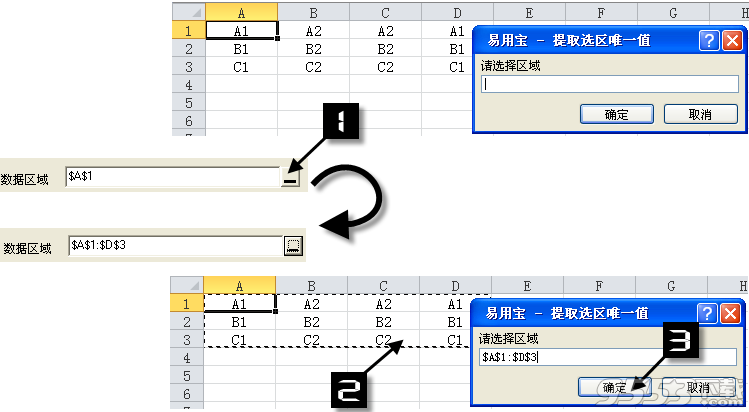
依次单击【数据对比】→【提取唯一值】,打开【提取选区唯一值】对话框。

在【提取选区唯一值】对话框中,各命令功能说明如下:
【数据区域】
【数据区域】文本框用于标示需要提取唯一值的源数据区域,默认为当前工作表的选中区域,无法直接在文本框中进行编辑修改。
单击【数据区域】文本框右侧的区域拾取按钮 可以打开【提取选区唯一值】区域拾取窗口,用鼠标拖曳选中目标区域,单击【确定】按钮就完成了【数据区域】文本框内容的更新。
【模式】
模式决定了检索重复值的搜索顺序,同时影响最终唯一值的排列顺序。模式包括【先行后列】和【先列后行】,图形演示了这两种模式的具体效果,下面简要说明之。
A、先行后列

因为是【先行后列】模式,在第1行检测中C1、D1单元格内容已经出现在A1:B1单元格区域,所以被删除。同理,C2、D2,C3、D3分别在第2行,第3行的检测中被删除。
在剩下的唯一值重组时依然按照【先行后列】模式,即先填满第1行,然后再填第2行,依次类推。因此A2:B2单元格区域的数据被搬迁到C1:D1单元格区域,A3:B3单元格区域的数据被迁移到A2:B2单元格区域。
B、先列后行
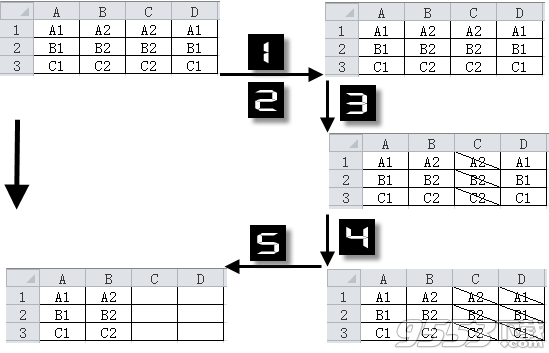
【先列后行】和【先行后列】原理相同,只是重复值检索的方向是从第1列开始从上到下,然后再从第2列开始从上到下,如图所示,第1、第2列都没有出现重复值,第3、第4列的值都在第1、第2列中出现了。
最后重组剩余的唯一值时,依次先填满第1列的数据,然后再填满第2列的数据,依此类推。本例剩余的唯一值正好为第1、第2列的数据。
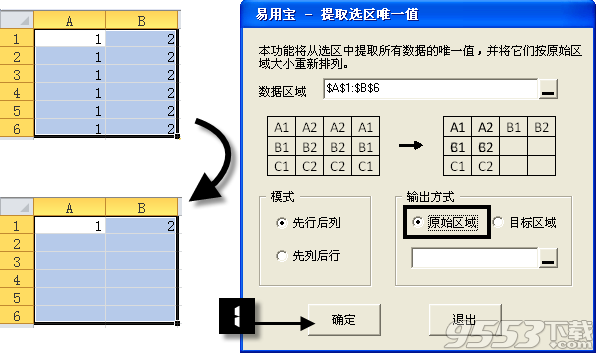
【输出方式】
输出方式有两个选项:【原始区域】和【目标区域】。选择原始区域,即将提取的唯一值将覆盖【数据区域】,这意味着原始的数据将被清除,清空数据区域再返回唯一值的原始区域输出方式。
注意:
使用【原始区域】方式将清除源数据区域,且无法恢复,建议使用【目标区域】比较妥善。
使用【目标区域】即将提取的唯一值返回到新的单元格区域,可以使用区域拾取按钮 进行选择。
使用技巧:
【数据区域】实质是选中区域,其中的空白单元格在检索重复值的过程中被忽略。但是,在将唯一值重新进行排布时,这些空白单元格与含有数据的单元格一样,都起到占位的作用。利用这一点可以通过选中不同大小和形状的数据区域来控制最终唯一值的排布,具体参见示例。
示例1:提取唯一值并整理为一整列
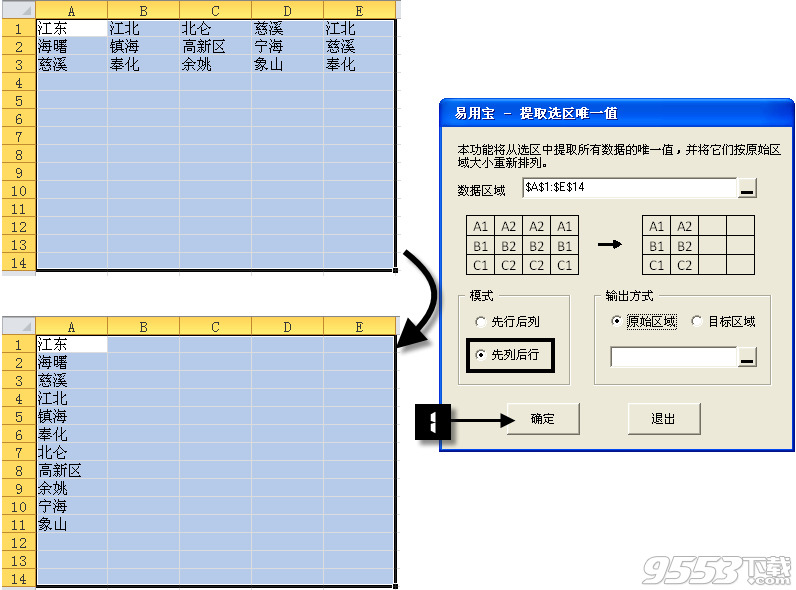
“提取唯一值并整理为一整列”的关键是选择足够大的单元格区域,使得单元格区域的行高大于最后的唯一值总数。这样在选择【先列后行】模式时,所有的唯一值都被填充到第一个列中,即得到一整列。
示例2:提取唯一值并整理为一整行
可以参考示例1,只是选择足够的列宽,使得最后的唯一值都能放入第一行,然后选择【先行后列】模式。
提示:
控制选中区域的行高、列宽可以控制最终唯一值的排布,如果无法一步到位,可以先将数据区域整理为单行、单列再进行处理。
比如数据区域为A1:A20,唯一值总数为18,如果要返回两列,那么需要设置行高为9,但这样无法完全选中A1:A20区域。这时可以将其返回为一整行,然后再设定行高为9,【先列后行】的模式分两步达到最终的要求。